redis cluster pipeline
08 Mar 2019redis cluster
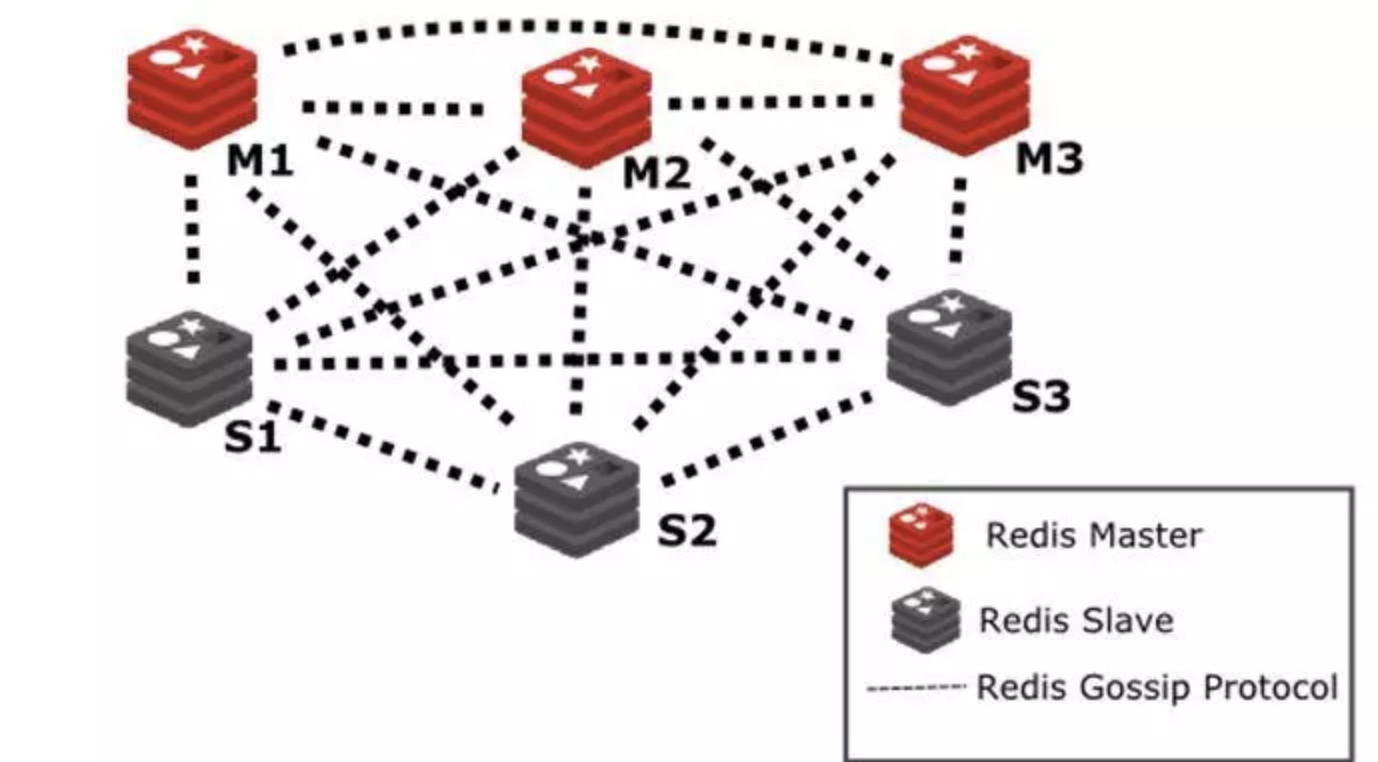
从3.0开始,redis开始支持集群模式。
-
无中心架构
- 按key将数据哈希到16384个slot上 HASH_SLOT = CRC16(key) mod 16384
- 集群中的不同节点分别负责一部分slot
从3.0开始,redis开始支持集群模式。
无中心架构
Cron是一个存在了很长时间的UNIX工具,它的调度功能很强大而且经过了验证。CronTrigger类基于cron的调度功能。 CronTrigger使用“cron表达式”,它能够创建类似这样的触发策略:“每周一至周五上午8:00”或“每月最后一个星期五凌晨1:30” Cron表达式很强大,但(规则)可能令人很困惑。 本教程旨在揭示撰写Cron表达式的一些谜团,为用户提供在论坛或邮件列表咨询之前可以访问的资源。
Cron表达式是由空格分隔的6或7个字段组成的字符串。 字段可以包含任何允许的值,以及该字段允许的特殊字符的各种组合。 字段如下:
| 字段 | 是否必须 | 允许值 | 允许特殊字符 |
|---|---|---|---|
| Seconds | 是 | 0-59 | , - * / |
| Minutes | 是 | 0-59 | , - * / |
| Hours | 是 | 0-23 | , - * / |
| Day of month | 是 | 1-31 | , - * ? / L W |
| Month | 是 | 1-12 or JAN-DEC | , - * / |
| Day of week | 是 | 1-7 or SUN-SAT | , - * ? / L # |
| Year | 否 | empty, 1970-2099 | , - * / |
所以cron表达式可以像这样简单:* * * * ? * 或者更复杂一些,像这样:0/5 14,18,3-39,52 * ? JAN,MAR,SEP MON-FRI 2002-2010
这里有点拗口,其实很好理解,就是day-of-month和day-of-week2个字段是互斥的,因为它们都表示的天。如果两者中有一个指定了值,另一个必须设置成”?”,用来区分。译者注。
即 /10 相当于 0/10。译者注
‘L’和’W’字符也可以在day-of-month字段中组合以产生’LW’,这转换为“最后一个工作日”。
法定字符以及一周中几个月和几天的名称不区分大小写。 MON与mon相同。
这是几个完整的例子:
| 表达式 | 含义 |
|---|---|
| 0 0 12 * * ? | 每天12:00点触发 |
| 0 15 10 ? * * | 每天10:15触发 |
| 0 15 10 * * ? | 每天10:15触发 |
| 0 15 10 * * ? * | 每天10:15触发 |
| 0 15 10 * * ? 2005 | 在2015年,每天上午10:15触发 |
| 0 * 14 * * ? | 每天,从14:00开始,到14:59结束,每1分钟触发 |
| 0 0/5 14 * * ? | 每天,从14:00开始,到14:55结束,每5分钟触发 |
| 0 0/5 14,18 * * ? | 每天,在14:00-14:55,18:00-18:55时间段内,每5分钟触发 |
| 0 0-5 14 * * ? | 每天,在14:00-14:05,每分钟触发 |
| 0 10,44 14 ? 3 WED | 每年3月的每个星期3,14:10和14:44触发 |
| 0 15 10 ? * MON-FRI | 每个星期一到星期五的10:15触发 |
| 0 15 10 15 * ? | 每月15日,10:15触发 |
| 0 15 10 L * ? | 每月最后一天,10:15触发 |
| 0 15 10 L-2 * ? | 每月距最后1天的前2天,10:15触发 |
| 0 15 10 ? * 6L | 每个月最后一个星期五的10:15触发 |
| 0 15 10 ? * 6L 2002-2005 | 在2002,2004,2004,2005年,每个月最后一个星期五的10:15触发 |
| 0 15 10 ? * 6#3 | 每个月第3个星期五的10:15触发 |
| 0 0 12 1/5 * ? | 从1日开始,每隔5天的12:00触发 |
| 0 11 11 11 11 ? | 每个11月的11:11触发 |
注意’?’ 和’*’ 在day-of-week和day-of-month字段中的用法!
Quartz包含一个“更新检查”机制,这个机制会尝试连接远端服务器,来检查是否有新版本可供下载。该检查是异步运行的,不会影响到启动/初始化,并且如果连接失败检查的节奏会逐渐衰减。如果运行检查时发现有更新,Quartz会通过打印日志的方式报告出来。
你可以使用Quartz配置属性“org.quartz.scheduler.skipUpdateCheck:true”或系统属性 “org.terracotta.quartz.skipUpdateCheck = true”(你可以在系统环境中设置或在java命令中以 -D的形式) 来禁用更新检查。 建议你生产环境部署时禁用更新检查。
在JobDataMap中只存储原始数据类型(包括String),短期和长期来看,这可以避免数据序列化问题。
在Job执行时,可以很方便的从JobExecutionContext中获取JobDataMap使用。此JobDataMap是从JobDetail和Trigger获取的JobDataMap的合并,且前者中同名的值会被后者覆盖。
你在调度器上的一个Job,可供多个Triggers定期/重复使用,此时将JobDataMap值存储在Trigger上,每次独立触发时,你的Job就可以获取不同的输入。
鉴于以上所有,以下是我们推荐的最佳实践:在Job.execute(..)的代码中,应该从JobExecutionContext中的JobDataMap获取数据,而不是直接从JobDetail中获取。
TriggerUtils:
直接想数据库写入调度数据(通过SQL)而不是使用scheduling API:
如果你将多于一个scheduler实例指向同一组数据库表,且这些实例没有配置集群模式,可能产生以下结果:
建议将数据源最大连接大小配置为至少为线程池中的工作线程数加3。如果您的应用程序也频繁调用调度程序API,则可能需要其他连接。 如果您使用的是JobStoreCMT,则“非托管”数据源的最大连接大小应至少为4。
注意: 过渡时间的细节和时钟向前或向后移动的时间因地点而异,详细参考:https://secure.wikimedia.org/wikipedia/en/wiki/Daylight_saving_time_around_the_world.
SimpleTriggers不受夏令时影响,因为它们总是以精确的毫秒时间触发,并重复精确的毫秒数.
因为CronTriggers在给定的小时/分钟/秒时触发,所以当DST转换发生时它们会受到一些奇怪的影响.
作为可能出现问题的一个例子,在美国的TimeZones /位置观察夏令时,如果使用CronTrigger并在凌晨1:00和凌晨2:00安排开火时间,可能会出现以下问题:
同样,时间和调整量的具体情况因地区而异。
其他基于沿日历滑动的触发类型(而不是精确的时间量),例如CalenderIntervalTrigger,也会受到类似的影响 - 但是不是错过了一次触发,或者两次触发,最终可能会让它的触发时间偏移一个小时。
长时间运行的job可能会阻止别的任务执行(如果线程池中所有的线程都是busy状态) 如果你需要在job执行线程中调用Thread.sleep(),这通常表明你的Job还没有准备好做接下来的工作,因为它需要等待一些其他条件(例如一些数据还没有准备好)。 一个更好的办法是,释放工作线程(exit the job),把资源留给其他的job。你可以让重新调度这个job,或者在退出前调度其他job。
一个job的execute方法应该包含try-catch块,处理所有可能的异常。 如果一个job抛出异常,quartz典型的做法是重新执行它(当然它多半再次抛出同样的异常)。如果一个job 捕获可能遇到的所有异常,处理他们,重新调度它自己,或其他任务,就能解决这个问题。
进行中的job,如果标记为“可恢复”,在scheduler失效后会被重新调度。这意味着一些job做的工作会被执行两次。 这意味着job需要被编码成幂等的方式。
不建议在Listener中做大量的工作,因为执行Job的线程和Listeners捆绑在一起。
每个listener的方法都应该包含try-catch代码块,处理所有可能的exception。 如果一个listener抛出一个异常,可能导致别的listeners不能被通知到,或者会中止job的执行。
一些用户会把quartz的Scheduler方法通过应用程序接口暴露出去。这看起来很有用,不过也极其危险。
你要确定不能让用户随意定义他们想要的Job类型。例如,quartz提供了一种预制的任务 org.quartz.jobs.NativeJob,这种Job可以执行任意的、他们事先定义好的原生系统命令(操作系统级别)。 同样,其他的任务例如SendEmailJob,包括其他任何有恶意意图的Job
为了更高效率,允许用户定义任意的Job,你可能都将会面临与OWASP和MITER定义的命令行攻击 相当的威胁。
Log4j (The original apache logging framework for java),很早以来,使用最为广泛的日志框架。
Commons Logging,Apache基金会所属的项目,是一套Java日志接口,之前叫Jakarta Commons Logging,后更名为Commons Logging。
SLF4J (Simple logging facade for java),类似于Commons Logging,是一套Java日志接口。
Logback,SLF4J日志接口的实现。
JUL (Java util logging),自Java1.4以来的官方日志实现。
是不是觉得很混乱?先看一段历史八卦吧:
早在1996年,E.U. SEMPER项目组(Secure Electronic Marketplace for Europe Research,欧洲安全电子交易研究所,欧盟建立的一个通过Internet进行货币支付的项目)就决定开发自己的tracing API,这套API就是Log4j的前身。其作者是Ceki Gülcü。后来这套api经过各种变种,最终成为Apache基金会项目中的一员。 期间Log4j近乎成了Java社区的日志标准。据说Apache基金会还曾建议sun引入log4j到java的标准库中,但Sun拒绝了(未求证)。
2002年Java1.4发布,Sun推出了自己的日志库,JUL(Java Util Logging),其实现基本模仿了Log4j的实现。
接着,Apache推出了Jakarta Commons Logging项目,JCL只是定义了一套日志接口(其内部提供一个Simple Log的简单实现),支持运行时动态加载日志组件的实现,也就是说,在你应用代码里,只需调用Commons Logging的接口,底层实现可以是Log4j,也可以是Java Util Logging。 即便Sun推出了官方的Log API,但很少有人用。
2006年,Ceki Gülcü不适应Apache的工作方式,离开了Apache(据说,未求证)。然后先后创建了SLF4J(日志门面接口,类似于Commons Logging)和Logback(SLF4J的实现)两个项目,并回瑞典创建了QOS公司(Quality Open Software,based in Lausanne, witzerland.),以在线销售Log4j Manual文档、SLF4J/Logback技术支持和为期2天的SLF4J/Logback技术培训为主营业务。
QOS官方网站上是这样描述Logback的:
一个通用,可靠,快速且灵活的日志框架。
Logback还声称:
某些关键操作,比如判定是否记录一条日志语句的操作,其性能得到了显著的提高。这个操作在Logback中需要3纳秒,而在Log4J中则需要30纳秒。LogBack创建记录器(logger)的速度也更快:13毫秒,而在Log4J中需要23毫秒。更重要的是,它获取已存在的记录器只需94纳秒,而Log4J需要2234纳秒,时间减少到了1/23。跟JUL相比的性能提高也是显著的。
此后一直持续到现今,Java日志领域被划分为两大阵营:Commons Logging和SLF4J。Commons Logging在Apache大树的笼罩下,有很大的用户基数。但有证据表明,形式正在发生变化。有人分析了GitHub上30000个项目,统计出了最流行的100个Libraries,可以看出一些端倪。
八卦完毕。是否Log4j,commons-logging,SLF4J,Logback之间的关系一下子就清晰了?
SLF4J/Logback对比commons logging/log4j的一些优势:
Commons logging,为了减少构建日志信息的开销,通常的做法是:
if(log.isDebugEnabled()) { log.debug(“User name: “ + user.getName() + “ buy goods id:” + good.getId()); }
在SLF4J中,你只需这么做:
log.debug("User name:{}, buy goods id :{}", user.getName(), good.getId());
也就是说,slf4j把构建日志的开销放在了它确认需要显示这条日志之后,减少了内存和cpu的开销,代码也更为简洁。但计算参数的开销并没有被推迟。比如:
log.debug("User name:{}, user’s password:{}", user.getName(), crypt(password));
这也是SLF4J仍保留isDebugEnabled方法的原因。
对于一个新项目,不要犹豫,使用SLF4J+Logback吧。 仅仅是这样么?答案是NO。 去看一看,你项目中使用的第三方jar吧。Spring依赖的是Commons logging,xSocket则使用Java Util Logging记录日志,如果只配置了Logback,你可能会丢失一部分日志甚至出错 有没有好的办法呢?当然有:使用桥接器! 桥接器是一个伪造的日志实现,它允许你将Commos logging收集的日志,重定向至SLF4J。
你唯一需要做的,就是将以下jar包引入你的工程:
log4j-over-slf4j-xx.jar //log4j to slf4j
jcl-over-slf4j-xx.jar //commos logging
jul-to-slf4j-xx.jar //java Util Logging
注意,如果你的工程中同时存在log4j-over-slf4j.jar,slf4j-log4j12.jar,你的日志会陷入死循环进而可能导致内存溢出。
日志记录请求级别为p,其logger的有效级别为q,只有则当p>=q时,该请求才会被执行。 该规则是logback的核心,其他各日志框架也遵循此规则。 Level排序为:
TRACE < DEBUG < INFO < WARN < ERROR。
Logger L可以手动分配级别。如果L未被分配,它将从父层次等级中第一个非Null继承。所以为了确保每一个logger都持有一个level,根logger需要持有一个level。 例如com.flyer,如果手动指定了,其有效Level即为手动指定。若未指定,从com继承。若com为null,从root logger继承。
列举一些常见的appender:
- ConsoleAppender,输出至控制台
- FileAppender,输出至文件
- RollingFileAppender,输出至可以滚动的文件。TriggeringPolicy,决定是否以及何时进行滚动,RollingPolicy,负责滚动。TimeBasedRollingPolicy 它根据时间来制定滚动策略
- SocketAppender,它通过序列化LoggingEven 将日志记录输出到远程。如果远程服务是关闭的,日志会被丢弃,其后台通过一个线程定时去尝试连接远程
- JMSTopicAppender和JMSQueueAppender,它允许将日志输出至JMS。
- SMTPAppender,输出至邮件服务器。
- DBAppender,输出至DB,支持DB2,MySQL,Oracle,SQLServer,PostgreSQL等。
- SyslogAppender,输出至*nix的syslog守护线程。
基于三值逻辑(ternary logic),允许把它们组装成链,从而组成任意的复合过滤策略。过滤器很大程度上受到Linux的iptables启发。
- DENY,立即被抛弃。
- NEUTRAL,交给下一个过滤器处理。
- ACCEPT,立即处理。
Logback的其他特性,例如排版规则,MDC(Mapped Diagnostic Context),JMX注册等可以参考Logback的官方文档。